作者:hws000(hws.000#163.com)
声明:版权所有,转载请联系作者。
出处:https://blog.simbot.net/2022/03/12/the-fastest-knn-search-algorithm/
创新方法应用于knn(k nearest neighbor)搜索,GPU加速效果非常惊艳,硬件的利用率达到90%以上,这效果英伟达都做不到。前无古人,后无来者!
1.搜索速度对比。
测试平台RTX 2080ti,使用TensorCore,输入输出均为half(半精度FP16)时,理论算力107TFLOPS;输入为int8(8位整数),输出为int时,理论算力214TOPS。
数据库大小为200万,搜索方式为暴力搜索,结果取Top1,距离计算方式为内积(等同于矩阵乘)。
算力=计算量/耗时,计算量=MxNxKx2。
knn搜索耗时包含排序的时间,但没有包含排序的计算量。
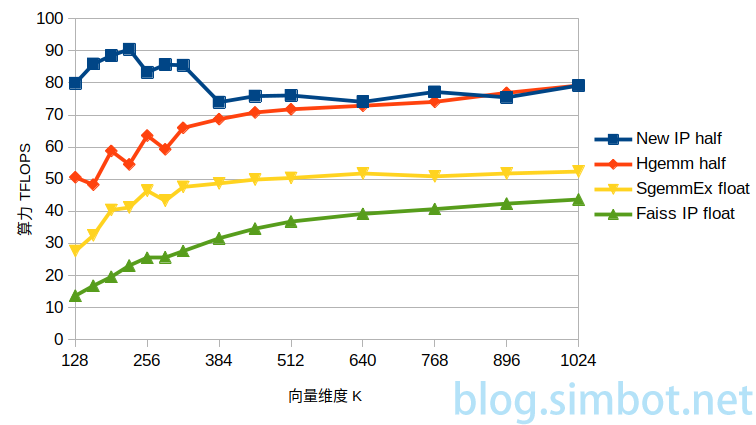
创新方法New IP(输出half);
矩阵计算函数cublasHgemm(输出half);
矩阵计算函数cublasSgemmEx(输出float);
现有开源方法Faiss IP(使用cublasSgemmEx函数,输出float)。
输入数据类型均为half ,输出half或float,在不同维度时的算力。
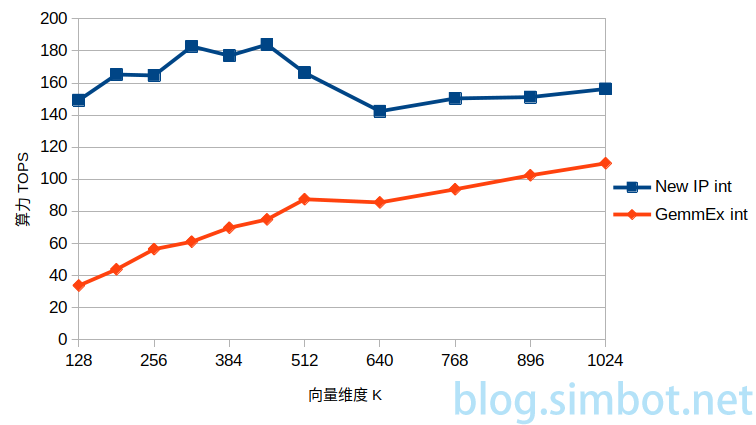
创新方法、矩阵计算函数cublasGemmEx,输入为int8,输出为int,在不同维度时的算力。
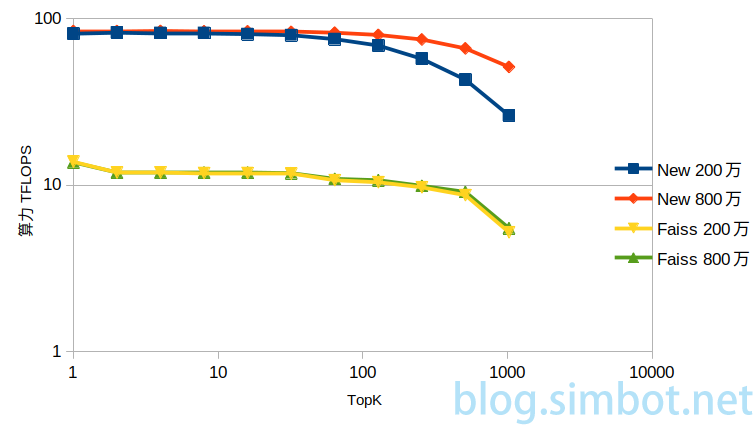
创新方法、faiss,在不同数据库大小,TopK取1、2、4…1024时的搜索效率。
创新方法在数据库越大时搜索效率越高。
下表为不同维度时,创新方法相对faiss的算力倍数。
knn搜索的数据维度一般在128~512之间,128维时是5.83倍,512维时是2.07倍。

2.算法介绍
算法的内容很简单,主要包含距离计算和排序两部分。
自己实现距离计算函数,计算出距离后立即过滤,只将符合过滤条件的结果写入显存,结果达到一定数量后再排序。
距离计算函数有多个优化点,过滤是最核心的一个,只写过滤后的结果,可以减少内存写入带宽,同时减少排序函数的读取带宽,间接减少排序函数的调用次数。
低维的距离计算函数也可以单独实现,由于维度低数据量小,查询数据可以常驻寄存器,计算过程中只需连续加载数据库的数据,可以提升数据加载效率。
比较紧凑的过滤语句也可以提高执行效率。
排序部分只是简单使用了双调排序,还至少有2-3倍的优化空间。
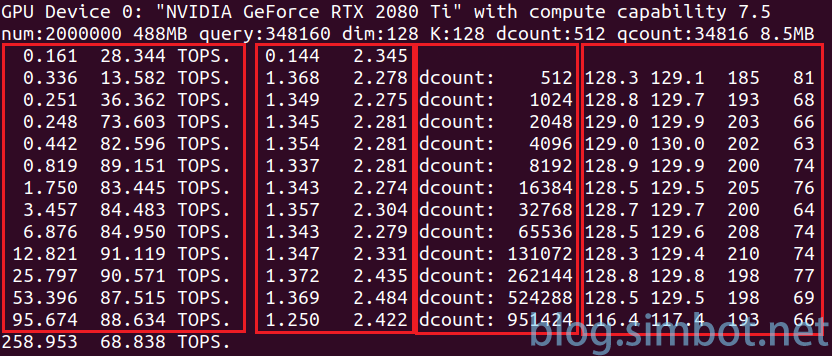
上图是搜索算法的一张执行截图,数据库大小200万,数据类型half,TopK为128,循环13次结束。
第一个红框是距离计算函数的执行时间(单位ms)和算力;
第二个红框是结果处理和排序的耗时;
第三个红框是当次循环的数据量;
第四个红框是过滤结果数的统计信息,分别为平均值、平方和的平均值、最大值、最小值。
每个循环处理的数据量均比上次翻倍,但结果数几乎不变。因此若总数据量翻1倍,循环次数加1。
红框中显示的是距离计算函数的算力,不包括排序部分,因此比最终的统计值高。
一次完整查询耗时258ms,调整参数减小查询量后,可以将耗时缩短到10ms以内。
3.结语
新算法通过专门针对向量计算进行优化,将硬件的利用率提升到90%以上,尤其在常用的128~512维度区间,表现效果比传统方法更好。新算法的瓶颈在硬件能力,堆更多的硬件可以有更高的算力。
knn算法是精确搜索,可以应用于人脸识别等场景,也可以用于构建图索引。
新算法理论上也可以在专业的矩阵加速卡上执行。
本算法受专利保护,专利号:CN114003630A。欢迎有需要的需求方合作。